Building a Context and Style Aware Image Search Engine: Combining CLIP, Stable Diffusion, and FAISS¶
This is a demonstration of what is possible with rapid prototyping and iterative refinement using AI dialogue engineering tools. This is a prototype of context-aware image locally running search engine that combines CLIP content relevance and Stable Diffusion style embeddings. This type of search could be useful for anyone with large collections of images that are difficult to search, online shops selling stock images or cards, museums or cases where images can't be put into cloud searches due to being business critical or classified.
Modern image search needs to go beyond simple metadata and tags. This application demonstrates how to build a sophisticated image search engine that understands natural language, visual content, artistic styles, and geographical context. Users can search their image collections using plain English descriptions, find visually and stylistically similar images, and even combine location data with visual similarity. Once models are downloaded, this search engine runs completely locally without the need for resources, APIs or models in the cloud.
A short demo searching my local collection of photos and images:
What makes this search engine special is its dual-model approach to understanding context and style. For example, you can search for "sunset over mountains in van gogh style" and it will find relevant images that match both the content and artistic style, even if they weren't explicitly tagged with those terms. You can then adjust the search by adding more terms like "with cypress trees" or "in Switzerland" and adjust how much weight to give to each query criteria.
Using FAISS allows the searching of huge quantities of images almost instantly, once the images have been indexed. My experiments have been on dataset collection of 10,000 images, although this would scale at least an order of magnitude higher.
Given the search process is creating latent representations of the search results, this could be expanded to generate similar images using Stable Diffusion. It would be a very good use of my previous Generative AI research that allows Stable Difussion's image generation to be steered by both a content relavence image and style guide image.
Examples¶
These examples are searching my local collection of photos and images.
Example 1: Search by content relevance¶
Enter a search term in plain English:

The search term is expanded into possible optimized search terms and weighting, which can be added to the search:
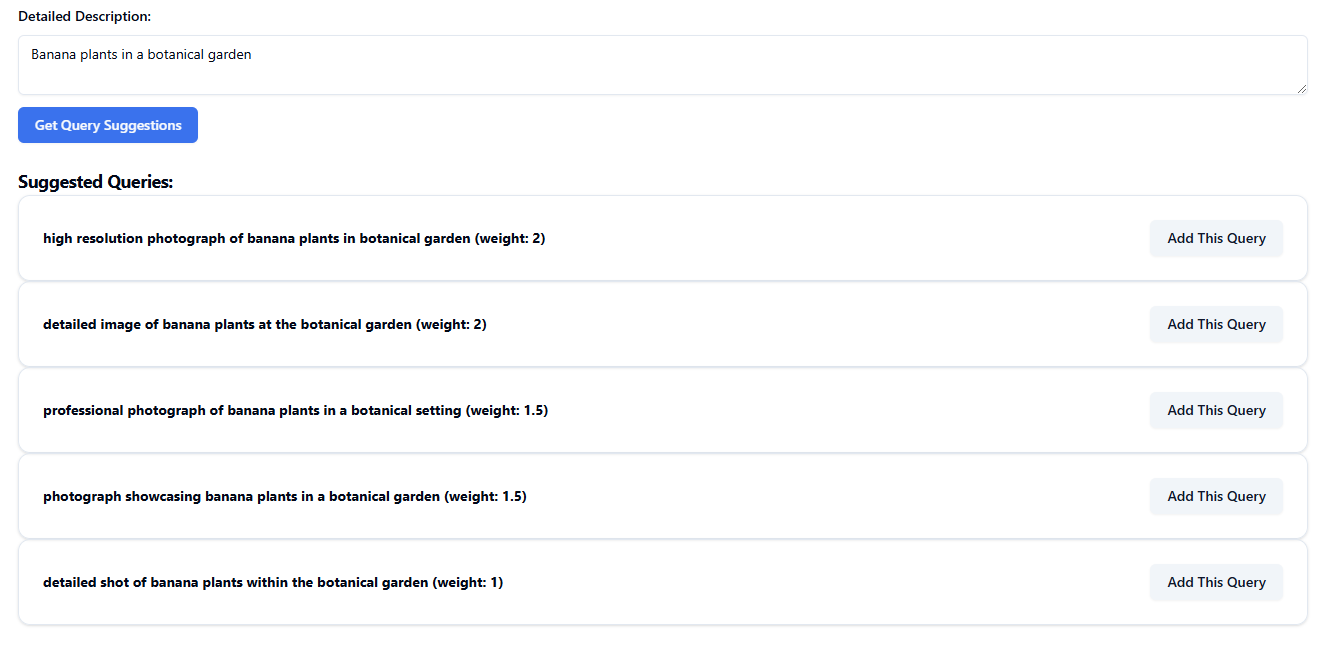
Additional search queries can be added, for example a location:
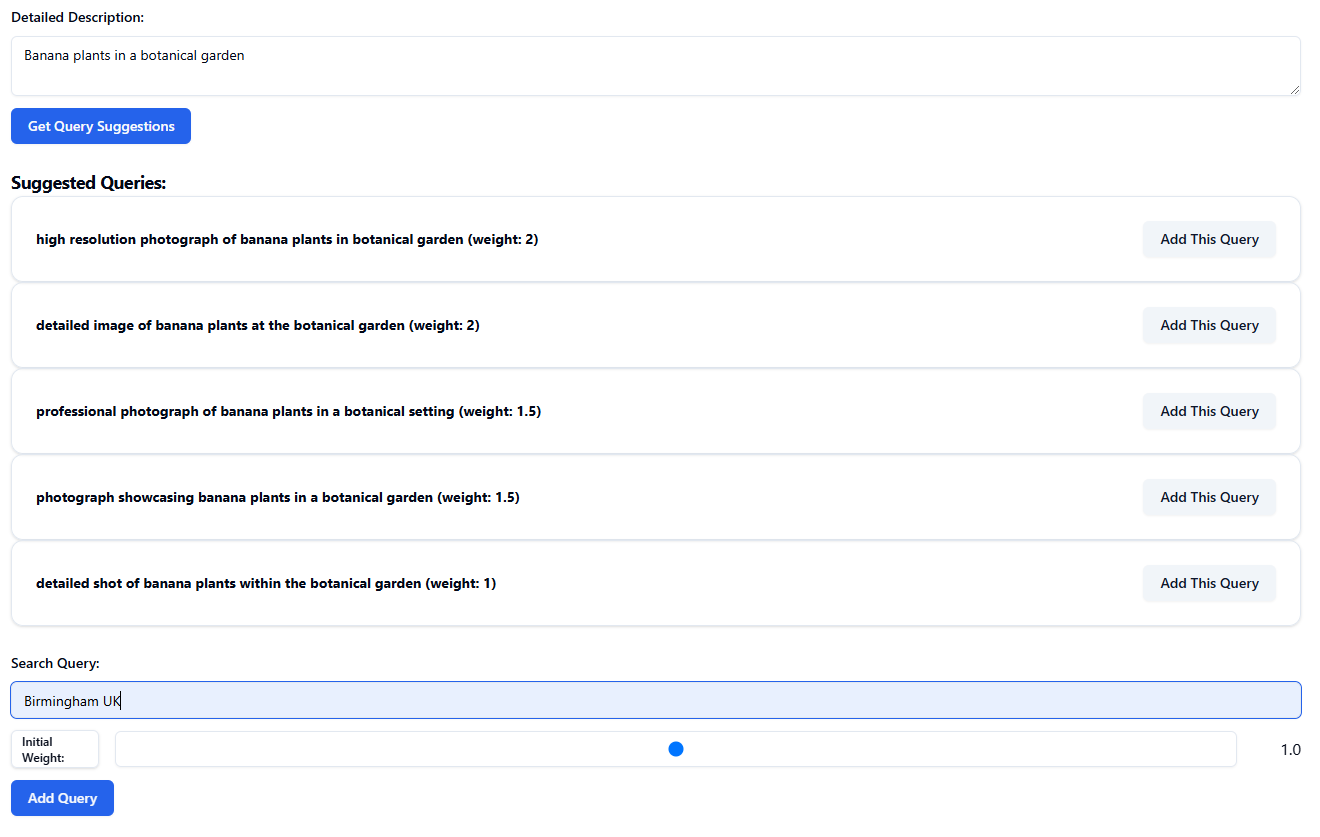
Search terms can have weightings adjusted:
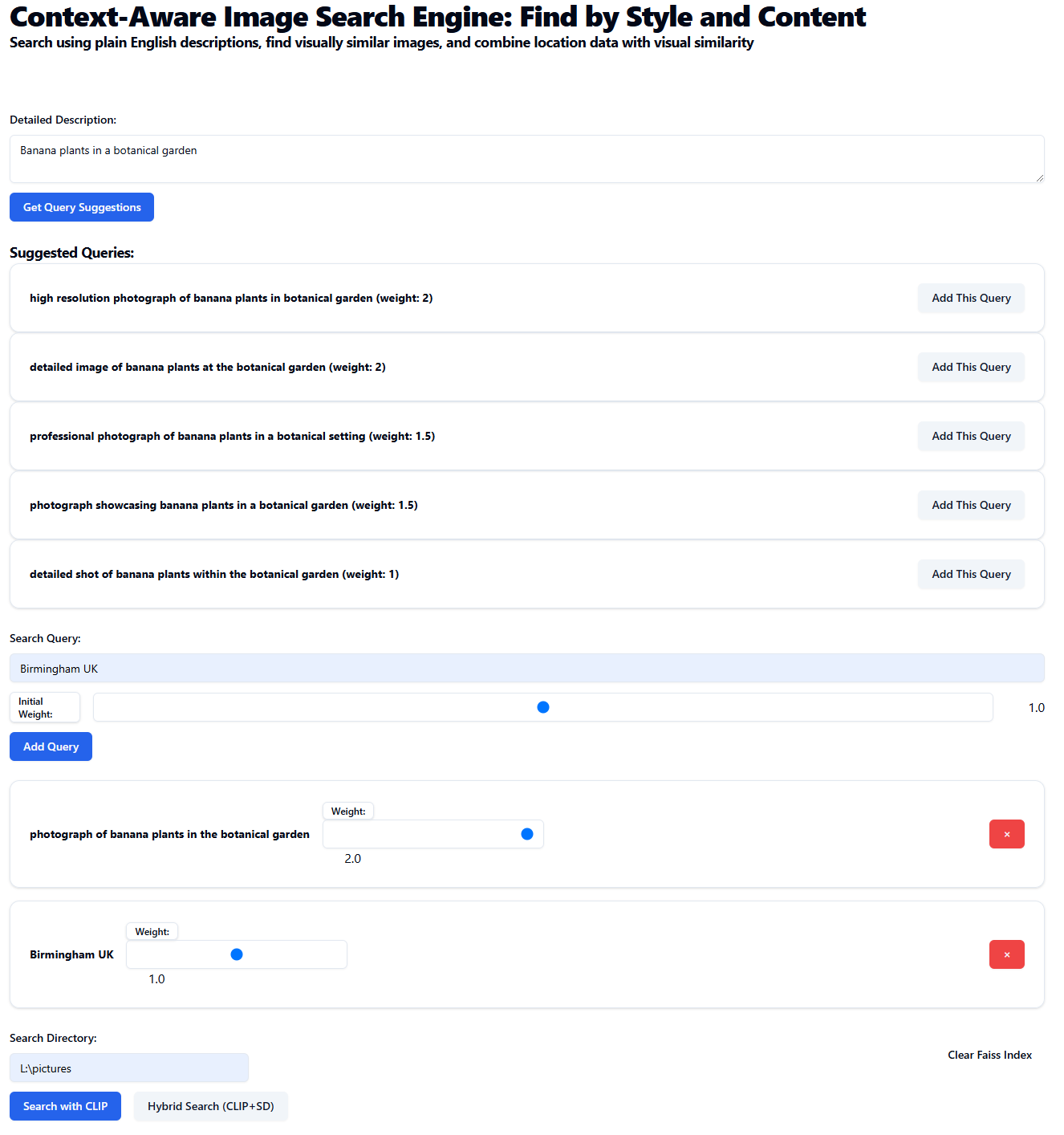
Results, showing a combined location and visual similarity score. Also, a distance where the images contain location EXIF data.
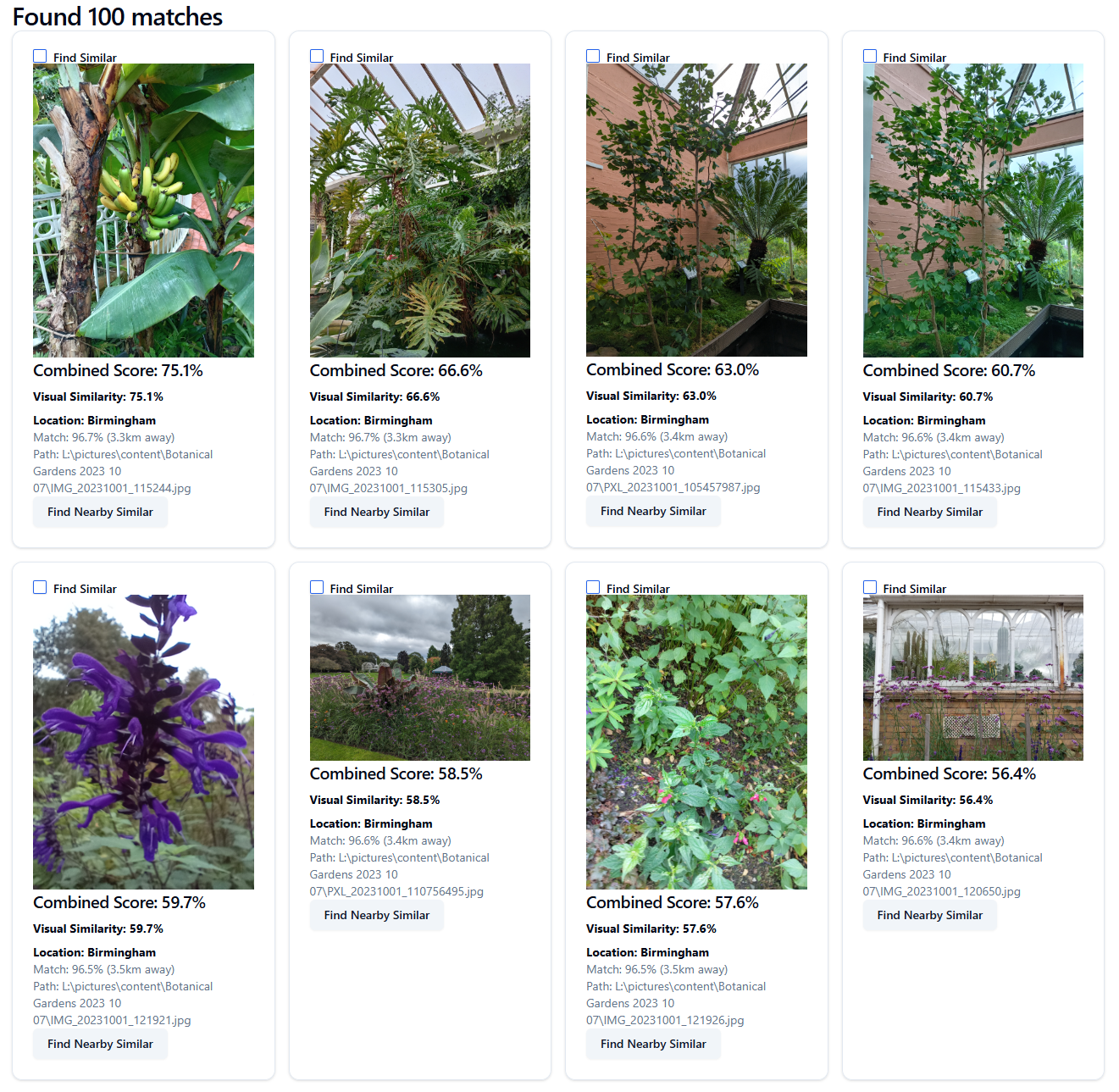
The search can be expanded with "Find Nearby Similar" button, which finds photos with similar content that were taken nearby where the images contain location EXIF data.
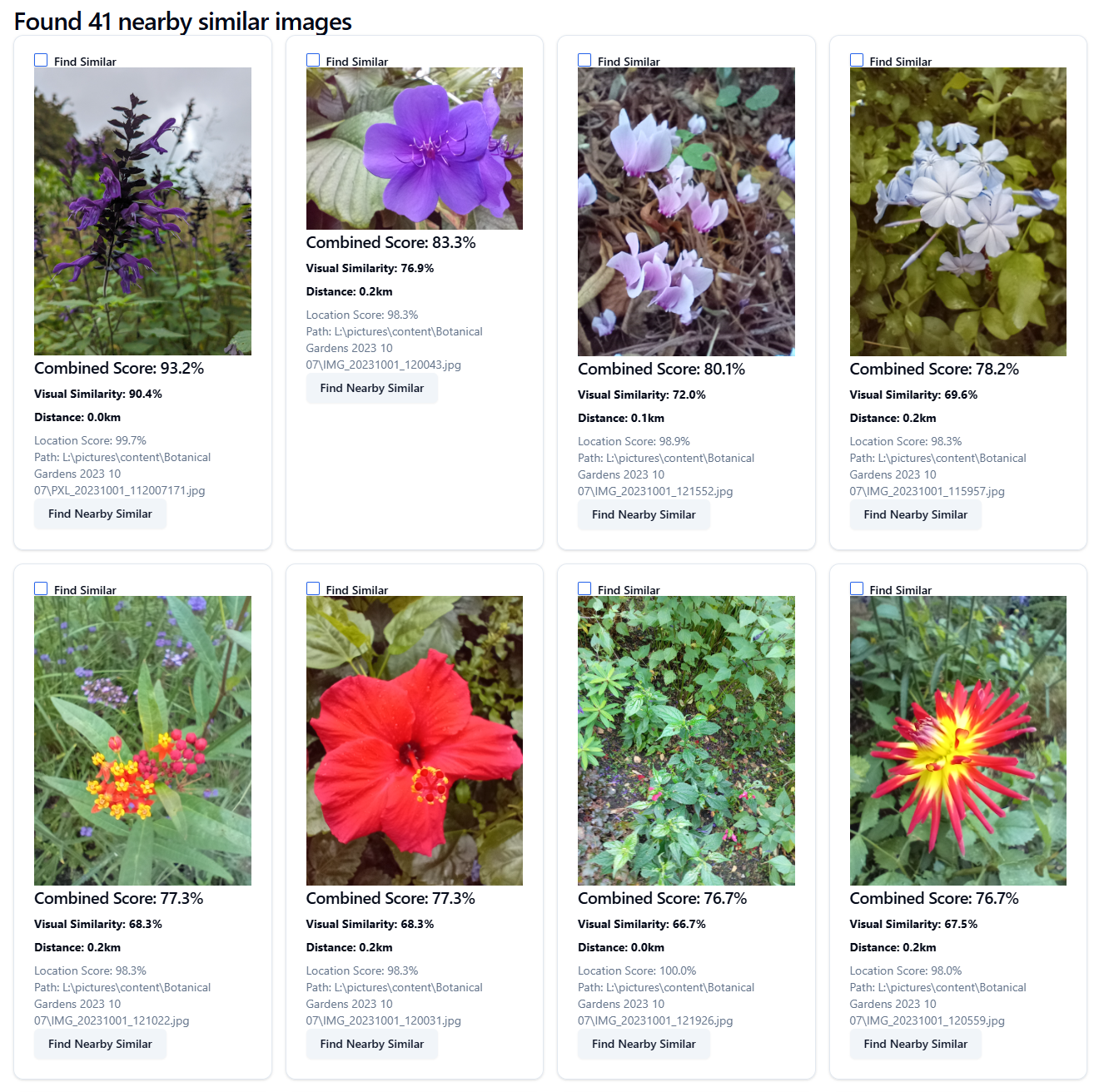
Alternatively one or more images can be selected to expand the search to images with similar content to them:
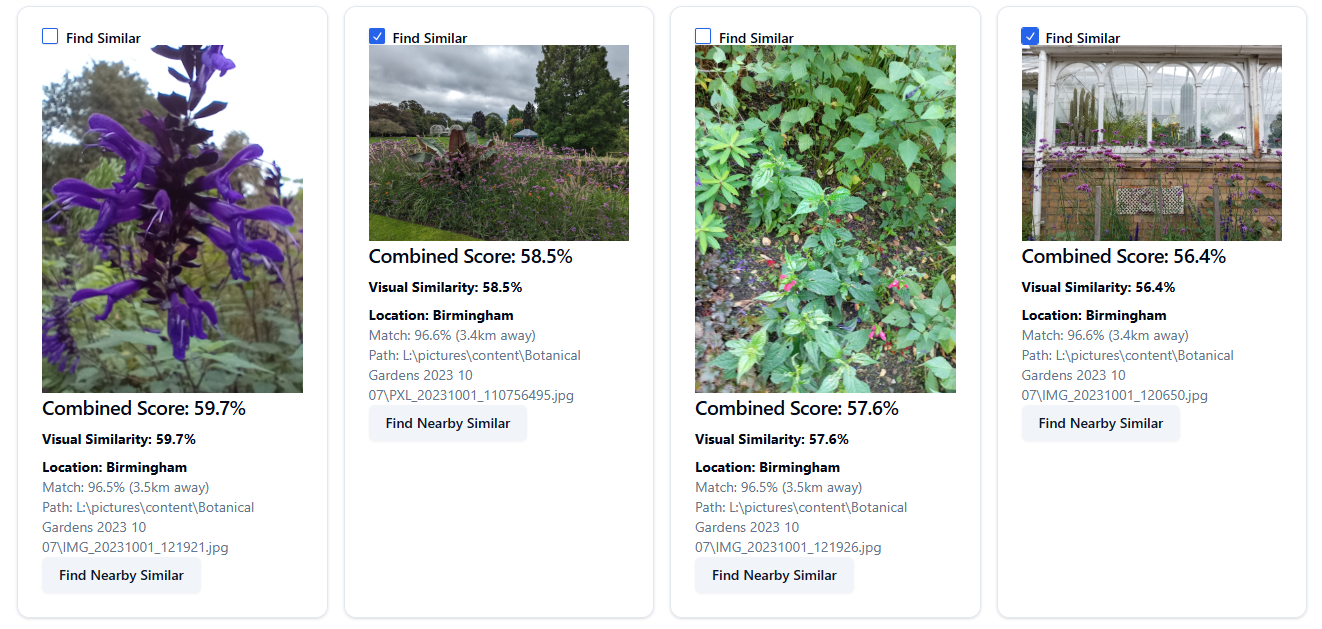
Results from selecting two images as a reference for similarity:
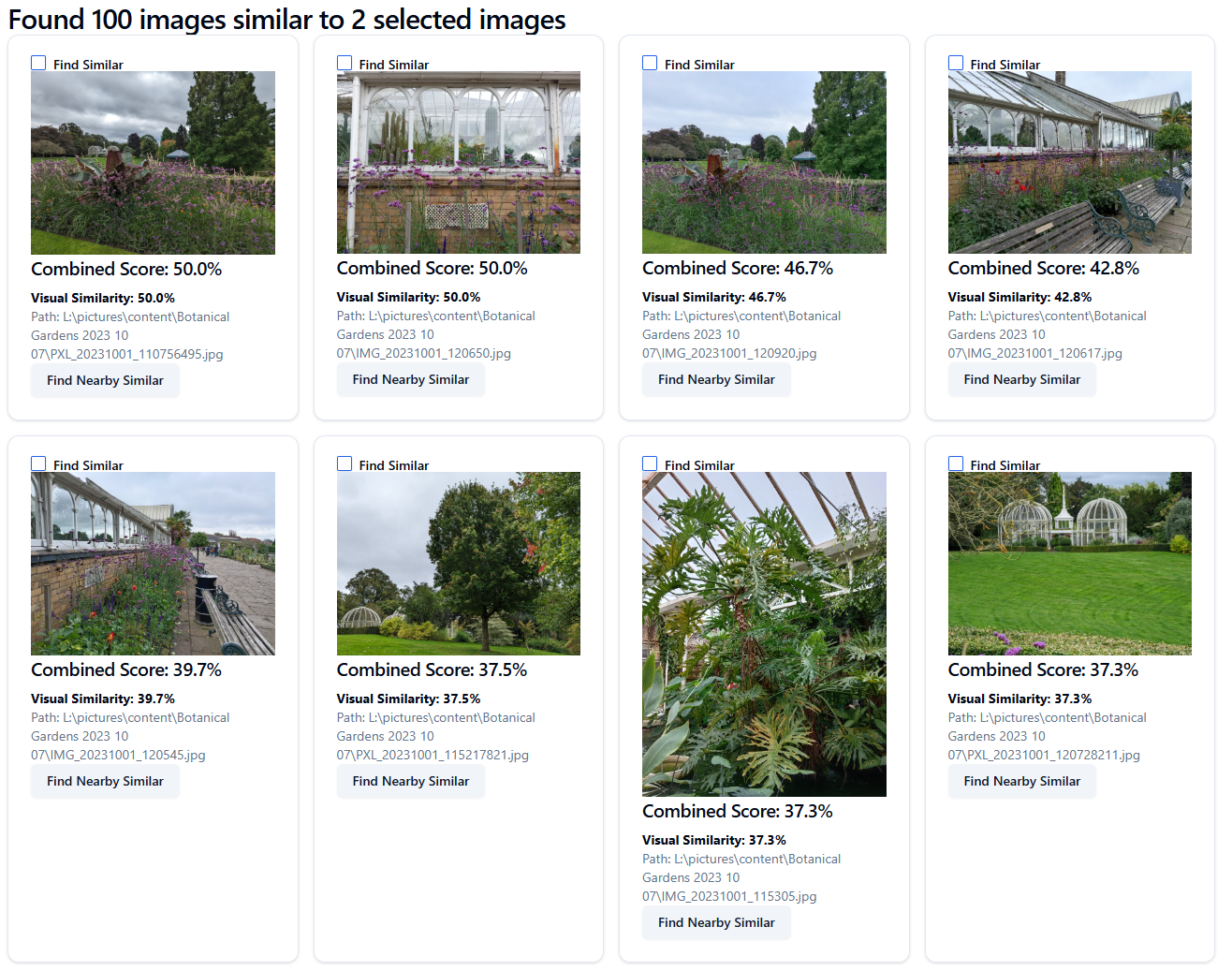
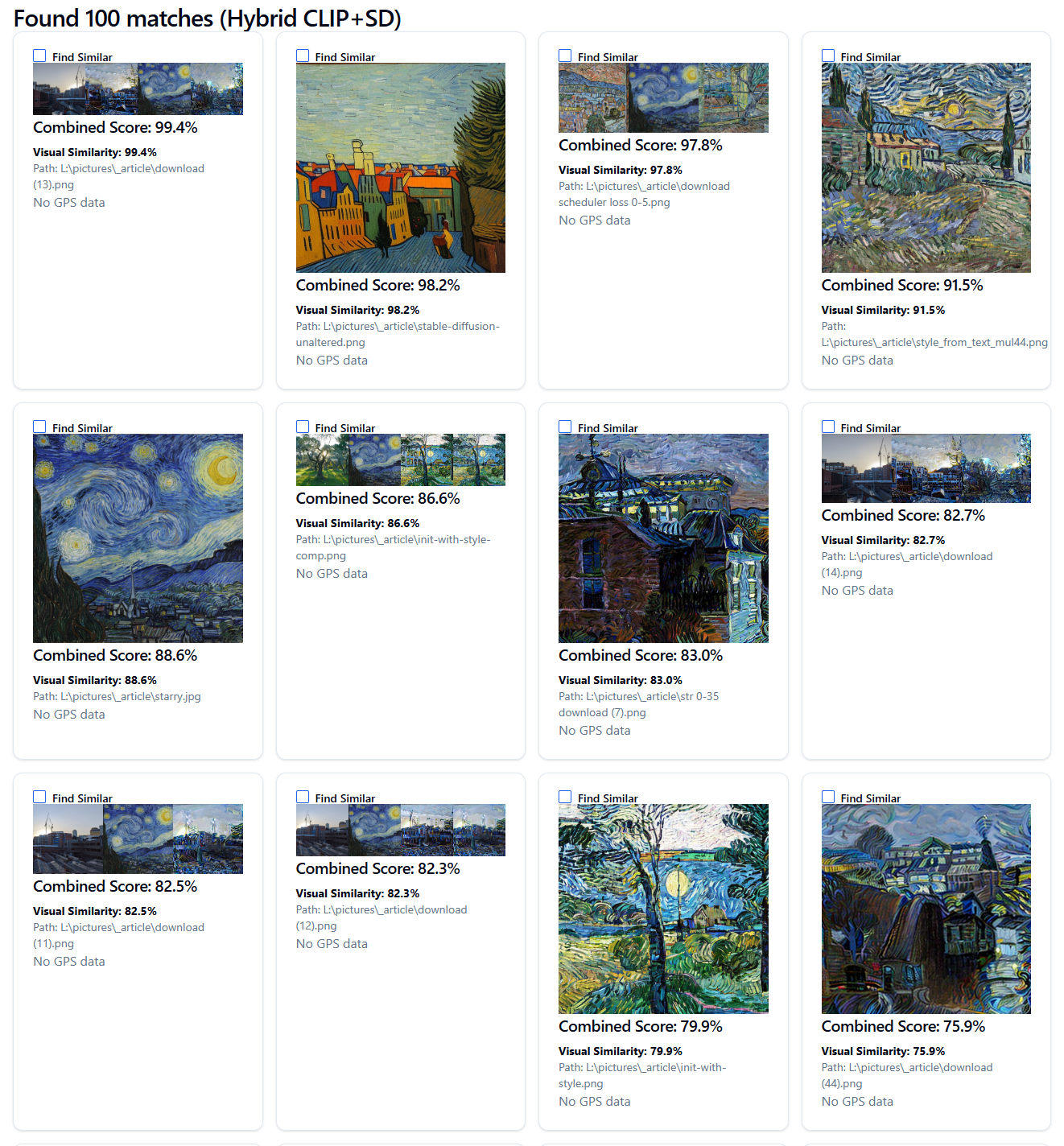
Example 2: Search by content relevance and also by style¶
The search for "van gogh style sunset" is expanded into optimized queries and one selected.
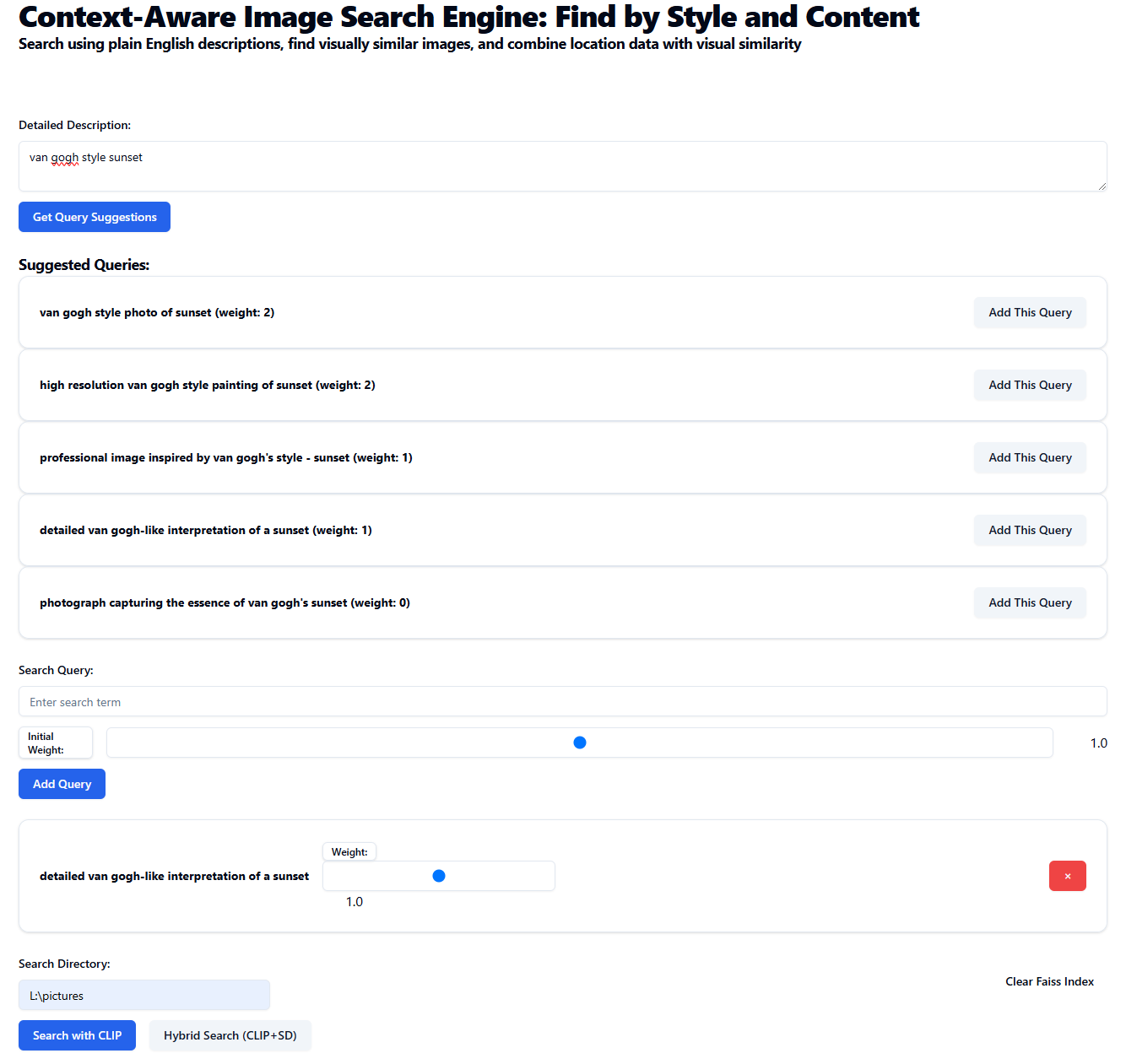
Using the Hybrid Search (CLIP and SD), the search results are based on both content relevance and Stable Diffusion style.
Core Technologies¶
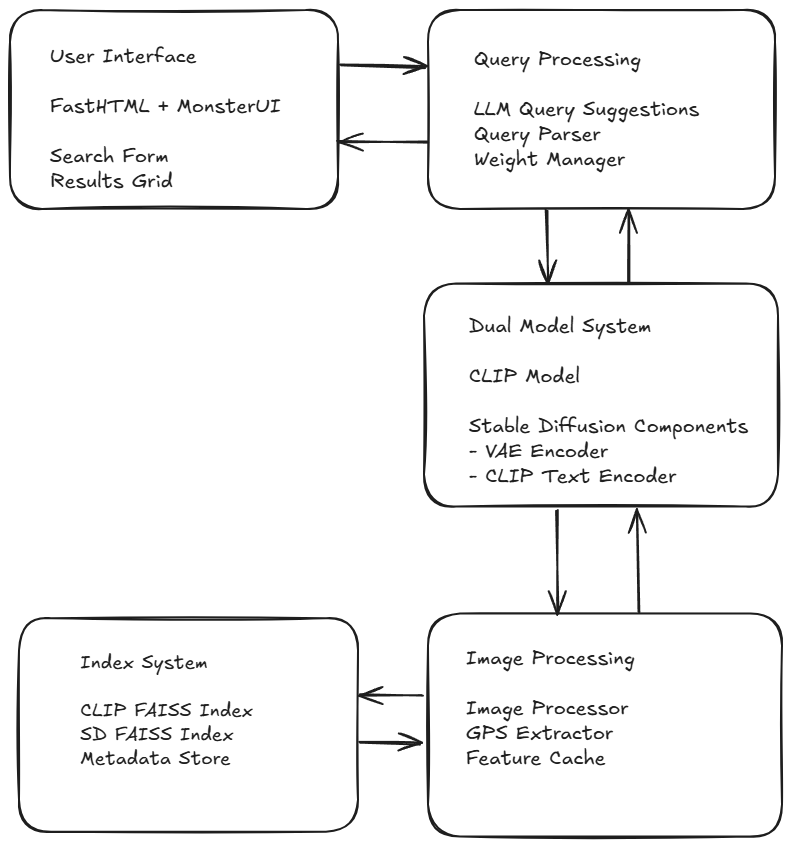
Hybrid Neural Search (CLIP + Stable Diffusion)¶
This search engine leverages two powerful AI models working in tandem. It uses the ViT-B/16 variant of CLIP and components from Stable Diffusion v1.4, offering an excellent balance between performance and resource usage.
CLIP Features:¶
- Architecture: Vision Transformer (ViT) with a 16x16 patch size
- Input Resolution: 224x224 pixels
- Embedding Dimension: 512
- Model Size: ~150M parameters
- Performance: 68.3% zero-shot ImageNet accuracy
- Strengths: General object and scene recognition
Stable Diffusion Components:¶
- VAE: For efficient image encoding
- CLIP Text Encoder: Specialized in artistic style understanding
- Embedding Dimension: 512 (matched to CLIP)
- Strengths: Artistic style and aesthetic comprehension
When you search for "sunset over mountains in van gogh style":
- CLIP converts the content aspects ("sunset over mountains") into a high-dimensional vector
- SD's text encoder processes the style aspects ("van gogh style")
- Both image and text are projected into their respective 512-dimensional embedding spaces
- The system combines scores from both models with configurable weights
- Results reflect both content relevance and style matching
This combination was chosen because:
- It is fast enough for real-time search
- Small enough to run on consumer GPUs
- CLIP excels at understanding concrete concepts
- Stable Diffusion components excel at artistic style comprehension
- Efficient memory usage when processing batches
The real magic happens when combining multiple searches - we can mathematically combine these vectors with different weights to find images that match multiple criteria simultaneously.
FAISS (Facebook AI Similarity Search)¶
These models provide powerful embeddings, although searching through them efficiently requires sophisticated indexing. This implementation uses dual FAISS indices:
Dual IndexFlatIP: Simple but effective exact search indices
- One for CLIP embeddings (512 dimensions)
- One for Stable Diffusion embeddings (512 dimensions)
- Optimized for cosine similarity search
- Good performance for collections up to ~100k images
- Full indices loaded into memory for fast searches
Storage Features:
- Separate persistent storage for each model
- Simple JSON metadata storage
- Fast load and save operations
Performance Features:
- Batch processing for efficient index updates
- Exact similarity search (no approximation)
- Support for incremental updates
Memory-mapped file support is available for handling large collections if needed.
FastHTML and MonsterUI¶
The user interface is built using FastHTML, a Python framework for server-rendered applications. This is enhanced with MonsterUI components combining the simplicity of FastHTML with the power of TailwindCSS. This combination provides:
- Real-time search results without page refreshes
- Responsive grid layout that adapts to screen size
- Smooth loading states and transitions
- Modal image previews
- Interactive weight adjustments for both models
- Style-specific UI controls for artistic searches
The UI is specifically designed to handle the dual-model approach:
- Visual indicators for which model found each match
- Preview thumbnails that highlight artistic elements
- Intuitive sliders for balancing model influence
Key Features¶
AI-Powered Query Suggestions¶
One of the most powerful features is the ability to get intelligent query suggestions using a Large Language Model. The system understands both CLIP's and SD's strengths and can suggest effective search terms optimized for each model.
1. Smart Query Generation¶
- Users can input a general description of what they're looking for
- The LLM converts this into multiple optimized search terms for both models
- Each term comes with a suggested weight and model assignment
For example, if a user inputs "I want to find impressionist paintings of people at the beach", the LLM might suggest:
- "People playing in the sand" (CLIP weight: 0.8)
- "Impressionist painting style" (Stable Diffusion weight: 0.9)
- "Beach activities" (CLIP weight: 0.7)
- "Loose brushwork texture" (Stable Diffusion weight: 0.6)
- "Sunny beach day" (CLIP weight: 0.4)
2. CLIP-Aware and Style-Aware Formatting¶
- Suggestions are formatted to match each model's strengths
- CLIP terms focus on concrete objects and scenes
- Stable Diffusion terms focus on artistic styles and techniques
- Balances specific and general descriptions
- Optimizes term combinations for hybrid search
3. Interactive Refinement¶
- Users can modify suggested weights
- Add or remove suggested terms
- Combine suggestions with their own queries
Multi-Model Search¶
The hybrid search system allows users to leverage both models' strengths:
1. Content Search (CLIP)¶
- Object recognition
- Scene understanding
- Spatial relationships
- Action recognition
- Color and composition
2. Style Search (Stable Diffusion)¶
- Artistic techniques
- Visual styles
- Aesthetic qualities
- Texture recognition
- Artistic periods
3. Location Awareness¶
- Extracts GPS coordinates from EXIF data
- Handles location-based queries
- Combines with both CLIP and Stable Diffusion results
- Geographic clustering of similar styles
For example, you could build a complex query:
- "Impressionist style" (Stable Diffusion weight: 0.8)
- "Garden scene" (CLIP weight: 0.7)
- "In France" (Location weight: 0.5)
- "With flowers" (CLIP weight: 0.6)
- "Monet-like brushstrokes" (Stable Diffusion weight: 0.4)
Similar Image Finding¶
The "Find Similar" feature now considers both visual content and artistic style:
1. Dual Similarity Analysis¶
- Uses CLIP for content similarity
- Uses Stable Diffusion for style similarity
- Optional content-only mode
2. Location Integration¶
- Optional geographic distance filtering
- Finds stylistically similar images from nearby locations
- Useful for finding different artistic interpretations of the same location
3. Combined Scoring¶
- Weighted combination of CLIP and Stable Diffusion scores
- Location proximity factoring
- Customizable similarity thresholds
Conclusion¶
This powerful combination of technologies creates a search engine that understands images both semantically and aesthetically. The integration of CLIP and Stable Diffusion components allows for unprecedented control over content and style-based searches, while the location awareness and multi-query capabilities provide a complete solution for sophisticated image search.
The system demonstrates how multiple AI models can work together to create intuitive and powerful tools for managing and exploring image collections. Whether you're an artist looking for stylistic inspiration, a photographer organizing your portfolio, or a researcher analyzing visual datasets, this system provides a sophisticated yet user-friendly solution.
This is an impressive demonstration of rapid prototyping and iterative refinement working with AI tools to speed up development.
References¶
- Github repo for this project
- FastHTML
- MonsterUI
- FAISS article
- FAISS repo
- Stable Diffusion on Hugging Face
- CLIP
P.S. Want to explore more AI insights together? Follow along with my latest work and discoveries here: