Improving LLM & RAG Systems: Essential Concepts for Practitioners¶
Building effective, production-ready LLM and RAG systems requires more than just theoretical knowledge. This intermediate guide outlines concepts and techniques for overcoming real-world implementation challenges, optimising performance, and ensuring system reliability. Whether you're scaling an existing deployment or planning your first production system, these essential insights will help you navigate the complexities of modern AI LLM & RAG architecture.
Expanded terminology¶
These are more indepth descriptions of some of the terminology from my basic LLM and RAG terminology article.
Prompt Engineering The art of crafting effective instructions for effectively communicating with AI models such as LLMs to achieve desired outcomes. This is often an repetative process performed by a specialist Prompt Engineer. Unlike traditional programming with deterministic results, prompt engineering is an exploratory process:
- It's inherently iterative – you refine prompts through repeated testing and adjustment
- There's no "perfect prompt" – only prompts that work well enough for your specific needs
- Success is measured by practical outcomes rather than theoretical perfection
- The process typically involves cycles of writing, testing, analysing results, and refining
- You stop when results consistently meet your requirements, not when you've found an "optimal" solution
Foundation Models Base versions of AI models trained on broad datasets, providing general capabilities that can be customised for specific needs. Foundation models undergo extensive pre-training on enormous text collections from the internet, books, code repositories, and other sources. This general training teaches them language patterns, factual knowledge, and basic reasoning abilities without focusing on specific tasks. Models like GPT-4, Claude, and Llama 3 begin as foundation models before any specialisation.
These models possess broad knowledge and flexible capabilities, allowing them to understand and generate text across numerous domains and topics. They demonstrate emergent abilities—skills they weren't explicitly trained for but developed through scale and exposure to diverse information. However, they may lack precision for specific applications and can sometimes generate plausible-sounding but incorrect information when operating outside their training boundaries.
Instruct Models Versions of foundation models specifically trained to follow instructions better, making them more reliable for business applications. These models are specifically optimised to understand and follow human instructions accurately, making them more suitable for practical business applications. These models undergo additional training beyond their base foundation model, using carefully crafted instruction-response pairs and human feedback to improve their ability to follow directions precisely.
Instruct models excel at following complex, multi-step instructions with greater precision and reliability. They stay focused on the task at hand, providing relevant responses that align with the user's intent. Their outputs are more consistent in format and style when specific structures are requested, and they generally demonstrate better alignment with human values and safety guidelines, reducing the likelihood of generating problematic content.
Implementing instruct models results in more predictable performance in production environments, with significantly less effort spent on complex prompt engineering. These models integrate more smoothly into existing business workflows and deliver better results on specific business tasks right out of the box. The improved reliability and reduced risk of inappropriate outputs make them particularly valuable for customer-facing applications where consistency and safety are paramount.
Models like Claude 3, GPT-4, Llama Chat, and Mistral Instruct are all instruction-tuned versions of more general foundation models.
The distinction between foundation and instruct models is becoming less clear as most commercial models now incorporate instruction tuning by default, but understanding this optimisation remains important when evaluating model capabilities.
Specialised Models: Code Generation
Models specifically trained or fine-tuned for programming tasks, offering enhanced capabilities for code generation, explanation, and debugging. These models understand programming languages, syntax, and development patterns, allowing them to generate functional code based on natural language descriptions. Most can work across multiple programming languages and frameworks, having been trained on extensive code repositories and programming documentation. Examples include GitHub Copilot (powered by OpenAI Codex), Claude Sonnet, GPT-4 Turbo, and specialised open models like WizardCoder and CodeLlama.
The development and use of these models is more like tuning a musical instrument than solving a math problem – you're seeking a practical level of performance that serves your specific development needs, not a theoretically perfect solution. This pragmatic approach has made code generation models valuable productivity tools for both experienced developers and those learning to code.
Performance Optimisation¶
Prompt Caching A performance optimisation technique that stores responses to frequently used prompts, eliminating redundant LLM calls. By identifying common or predictable queries and their corresponding outputs, systems can bypass the LLM for these cases, reducing latency and costs while maintaining consistent responses for standard interactions
Model Fallback Chains Architectures that try progressively more capable (but expensive) models when simpler ones fail to produce adequate responses. Well-designed fallback systems typically start with lightweight models for efficiency, escalate to more powerful models based on confidence scores or complexity metrics, route specialised queries directly to appropriate domain-specific models, and carefully manage cost-performance trade-offs throughout the process. This approach optimises both performance and resource utilisation.
KV Caching Memory optimisation technique that stores previously computed key-value pairs during generation, significantly improving inference speed by avoiding redundant calculations.
Speculative Decoding A technique that uses smaller, faster models to predict the outputs of larger models, then verifies these predictions. This significantly improves generation speed with minimal quality loss.
I have an article dedicated to Speculative Decoding.
Model Quantisation Reducing the precision of model weights to decrease memory requirements and increase inference speed, with minimal quality loss.
Tokens Per Second (TPS) A performance metric indicating how quickly a model can generate output, directly affecting user experience.
Streaming Responses Delivering AI-generated text incrementally rather than waiting for the complete response, improving perceived responsiveness.
Top-p and Top-k Settings that control how the model selects words when generating text, affecting creativity and consistency.
Stop Tokens Special markers that tell the model when to end generation, preventing rambling responses and ensuring concise outputs.
Maximum Token Limits Hard constraints on input and output size that require careful management to avoid truncation or errors.
API Rate Limits Restrictions on how frequently you can call LLM services, affecting system architecture and scaling strategies.
Multi-modal Capabilities The ability of advanced models to process both text and images together, enabling analysis of visual content alongside text.
Cost Management¶
Joules Per Token Energy consumption metric for AI inference, crucial for understanding environmental impact and operational costs. Larger models can consume 10-100x more energy than smaller ones.
Cost Optimisation Strategies Techniques to reduce LLM usage expenses while maintaining performance. This includes caching frequent queries to avoid redundant processing, right-sizing models by selecting the smallest model that meets quality requirements, optimising prompt length to reduce token consumption, batching multiple requests together for more efficient processing, and using embeddings efficiently to minimise vector database costs. These approaches can significantly reduce operational expenses, particularly for high-volume applications.
Semantic Caching Storing responses for semantically similar (not just identical) queries to improve efficiency and reduce costs.
Prompt Engineering Techniques¶
Prompt Templates Standardised formats for structuring inputs to LLMs, often including variables that can be filled dynamically.
Chain of Thought Prompting Guiding models to break down complex reasoning into explicit steps, significantly improving accuracy for difficult tasks.
Hybrid Prompt Strategies Combining different prompting techniques for improved performance across various tasks. Effective hybrid approaches include:
- Combining few-shot examples with chain-of-thought reasoning to guide complex problem-solving.
- Integrating role-based prompting with structured output requirements for consistent formatting.
- Using system prompts alongside dynamic examples tailored to specific queries.
- Interleaving instructions with demonstrations to clarify expected behavior.
These combined strategies often achieve better results than any single approach.
Security & Safety¶
Prompt Injection Prevention Methods to protect AI systems from manipulation through carefully crafted inputs that might override system instructions. Effective approaches include input sanitisation to remove potentially malicious content, instruction reinforcement that repeatedly emphasises system guidelines, role separation that isolates different system components, and context boundary enforcement that prevents user inputs from being interpreted as system instructions. These protections are essential for maintaining system security and reliability.
Content Moderation Integration Methods for filtering inappropriate content in AI systems to ensure safe and appropriate outputs. Comprehensive approaches include pre-processing user inputs to identify problematic queries before processing, post-processing model outputs to catch inappropriate responses, integrating with specialised moderation APIs for advanced detection, implementing custom moderation rules tailored to specific use cases, and applying safety classification systems that categorise content by risk level. These safeguards are essential for responsible AI deployment.
Monitoring & Evaluation¶
A/B Testing Infrastructure Systems for scientifically comparing different prompt strategies, model configurations, or retrieval approaches in production. These frameworks enable controlled experiments that measure the impact of changes on key metrics, helping teams make data-driven decisions about which improvements to adopt.
Observability Systems Comprehensive monitoring solutions for LLM applications that provide visibility into performance and behavior. These systems typically include usage tracking to monitor consumption patterns, error detection to identify issues, performance monitoring to track response times and quality metrics, cost analysis to optimise expenditure, and quality assessment to ensure outputs meet standards. Robust observability enables proactive management and continuous improvement of AI systems.
LangFuse An open-source observability and analytics platform designed specifically for LLM applications. LangFuse provides comprehensive monitoring, tracing, and evaluation capabilities that help teams understand how their LLM systems are performing in production. The platform captures detailed logs of prompts, completions, and metadata throughout the application flow, enabling developers to trace complex interactions, identify bottlenecks, detect failures, and analyze usage patterns. With features for custom evaluation metrics, user feedback tracking, and cost monitoring, LangFuse helps organisations optimise their LLM applications based on real-world performance data rather than theoretical benchmarks.
User Feedback Integration Systems for collecting and incorporating user feedback to improve LLM performance over time. Effective approaches include implementing thumbs up/down mechanisms for simple satisfaction tracking, creating correction workflows that capture specific improvements, developing preference learning systems that adapt to user preferences, and establishing continuous improvement cycles that systematically incorporate feedback into system refinements. These feedback loops are essential for ongoing system optimisation based on real-world usage.
Retrieval Metrics Quantitative measures for evaluating retrieval quality, including precision, recall, mean reciprocal rank (MRR), and normalised discounted cumulative gain (nDCG). These metrics help teams objectively assess and compare different retrieval strategies beyond just subjective quality assessment.
Evaluation Metrics Measurements for assessing LLM performance in production environments. Key metrics include response latency (time to generate outputs), completion accuracy (correctness of responses), instruction following (ability to adhere to specified guidelines), factual correctness (accuracy of information provided), and consistency across runs (reliability of similar outputs for similar inputs). Establishing clear metrics enables objective assessment of system performance and guides improvement efforts.
Evaluation Metrics¶
Relevance How well retrieved information addresses the specific query. High relevance means the system consistently returns information that directly answers user questions.
Coherence The logical flow and consistency of generated text. A coherent response presents ideas in a well-structured manner without contradictions or non-sequiturs.
Groundedness The extent to which a generated response is factually supported by the retrieved information. Highly grounded responses make claims that can be directly verified in the source documents.
Faithfulness Similar to groundedness, this measures whether the model's output accurately represents the information in the retrieved documents without adding unsupported details.
Latency The time taken to process a query and generate a response. Lower latency provides a better user experience but may require trade-offs with other qualities.
Toxicity The presence of harmful, offensive, or inappropriate content in generated responses. Effective systems minimise toxicity while maintaining helpful responses.
Hallucination Rate The frequency with which a system generates information not supported by retrieved documents or known facts. Lower rates indicate more reliable systems.
Conversation & Context Management¶
Chat History Management Techniques for tracking conversation context over multiple turns while managing token limitations. Effective approaches include summarising previous exchanges to capture essential information while reducing token count, selectively retaining the most relevant parts of conversation history, optimising context window usage through strategic truncation, and applying compression methods that preserve semantic meaning while reducing token consumption. These techniques are essential for maintaining coherent multi-turn conversations within context limits.
Multi-turn Conversation Design Techniques for creating natural, context-aware dialogue flows that maintain coherence across multiple interactions. This includes implementing context preservation strategies that maintain relevant information throughout a conversation, developing reference resolution capabilities that correctly interpret pronouns and indirect references, employing topic tracking mechanisms that follow conversation threads even as they evolve, and maintaining conversation state to ensure appropriate responses based on interaction history. These techniques create more natural and effective conversational experiences.
Context Window Utilisation Strategies for efficiently using the limited context space available in LLMs.
This includes strategic truncation of less relevant content to focus on what matters most, dynamic context management that adjusts based on specific query needs, and prioritisation mechanisms that favor recent or highly relevant information. Effective utilisation also involves carefully balancing detailed prompt instructions with actual content, implementing semantic chunking that breaks text along meaningful conceptual boundaries rather than arbitrary limits, leveraging retrieval augmentation to store content externally and fetch only what's needed for specific queries, and applying summarisation techniques to compress historical conversation turns while preserving their essential meaning.
These approaches help maximise the value derived from available context space, which directly impacts both performance and cost efficiency.
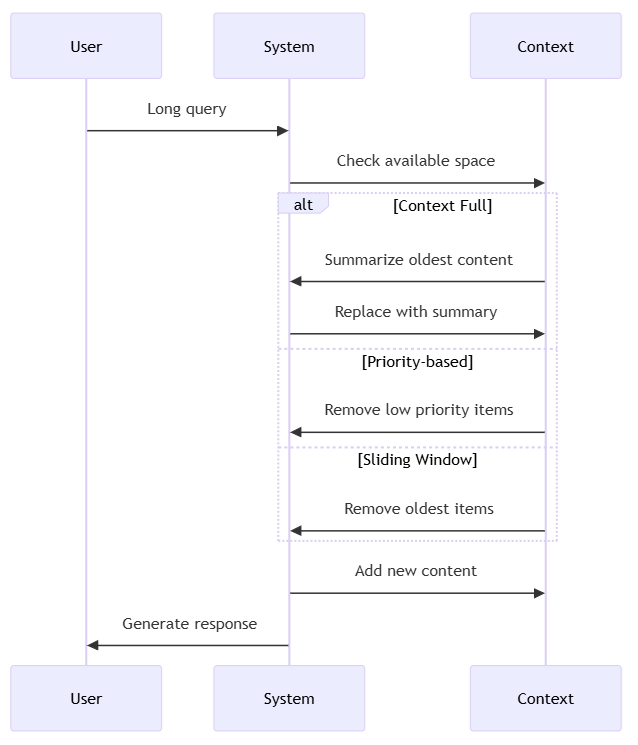
Context Compression Techniques Methods to fit more information into limited context windows while preserving essential meaning. Effective techniques include semantic compression that prioritises conceptual information over verbatim text, redundancy elimination that removes repeated or implied information, information prioritisation that emphasises the most relevant content, summary generation that condenses lengthy content, and key information extraction that identifies and preserves critical data points. These approaches maximise the effective capacity of context windows.
System Reliability & Error Management¶
This section focuses on techniques to build robust LLM applications that can handle unexpected inputs, model limitations, and potential failures gracefully.
Error Handling and Resilience Strategies for managing AI failures gracefully in production systems. This includes implementing systems to detect and recover from hallucinations by cross-checking outputs against reliable sources, using retry logic with exponential backoff for handling temporary service disruptions, creating fallback mechanisms that provide alternative responses when primary methods fail, and applying response validation techniques to ensure outputs meet quality thresholds before delivery to users. These approaches help maintain system reliability even when individual components experience issues.
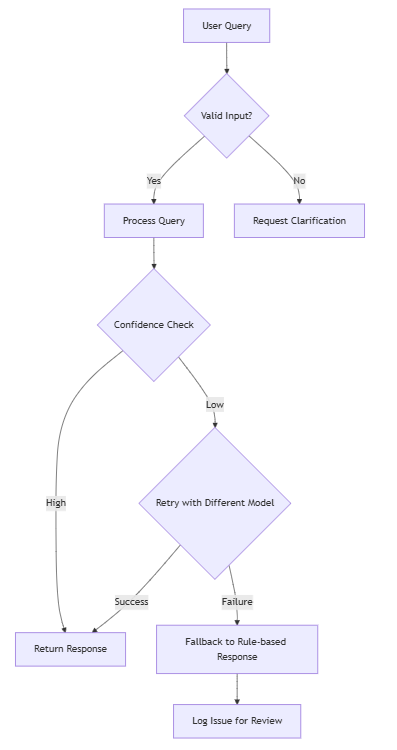
Response Validation Techniques to verify AI outputs meet requirements before delivery to users or systems. This includes schema validation to ensure structured responses match expected formats, factual consistency checking to verify information accuracy, business rule compliance verification to confirm outputs align with organisational policies, and output sanitisation to remove potentially harmful or inappropriate content. Implementing robust validation creates a quality control layer that significantly improves system reliability.
Defensive Coding Practices Implementation strategies to handle unreliable or inconsistent LLM outputs in production systems. This includes implementing robust error handling that gracefully manages unexpected responses, thorough input validation to prevent problematic queries, comprehensive type checking to ensure outputs match expected formats, sensible default fallbacks that provide reasonable responses when primary methods fail, and graceful degradation paths that maintain core functionality even when optimal performance isn't possible.
Model Alignment The degree to which an LLM's outputs match human values and expectations, including safety, helpfulness, and honesty considerations.
A/B Testing Frameworks Systems for comparing different prompting strategies, model configurations, or system designs to identify optimal approaches.

Output Control & Integration¶
Structured Output Methods to constrain LLM responses to specific formats like JSON, XML, CSV, or custom structures, making them more reliable for system integration. This is essential when responses need to be processed by other software rather than read by humans.
JSON Mode A specialised setting that ensures AI outputs follow strict JSON format for easier integration with other systems. This is particularly valuable for web applications and APIs where JSON is the standard data exchange format.
Function Calling A capability allowing AI models to interpret user requests and convert them into structured function calls with appropriate parameters. This enables models to trigger specific actions in external systems, such as searching databases, creating calendar events, or processing transactions.
Function Parameter Design Best practices for defining function parameters that LLMs can reliably use when interacting with external systems. Effective designs include using enumerated types where possible to constrain choices, providing clear parameter descriptions that explain purpose and constraints, including example values to demonstrate expected formats, defining proper data types to ensure compatibility, and setting appropriate defaults to handle missing information. Well-designed parameters significantly improve the reliability of AI-system integrations.
Parallel Function Calling The ability to invoke multiple external functions simultaneously, significantly improving efficiency for complex operations that don't depend on sequential execution.
Strict Mode Settings that enforce rigid output formatting and validation, helping ensure model responses follow exact specifications. Implementation varies across providers - some call this "function calling" or "structured output" rather than "strict mode," but the concept is similar: enforcing specific output formatting to increase reliability.
Pydantic Integration Using Python's Pydantic library to define strict data models for LLM outputs, ensuring they match expected formats and types. This creates reliable interfaces between AI and other systems.
Response Formatting Control Methods to guide the style, tone, and structure of LLM outputs beyond content. This includes implementing format specifications that define the exact structure of responses, applying style directives that control writing style and voice, setting length constraints to ensure appropriately sized outputs, managing tone to match brand voice or situational requirements, and adjusting complexity to match audience needs. These controls help ensure AI-generated content aligns with organisational standards and communication goals.
Tool Use Framework Design Architectures for enabling LLMs to use external tools effectively within applications. Well-designed frameworks include standardised tool description formats that models can understand, robust parameter validation to prevent errors, comprehensive error handling protocols for when tools fail, intelligent tool selection logic to choose appropriate tools for specific tasks, and result processing capabilities to incorporate tool outputs into responses. These frameworks extend LLM capabilities beyond text generation to complex task completion.
Development & Management Tools¶
Prompt Registries Centralised systems for managing, versioning, and deploying prompts as organisational assets, similar to code repositories.
Instruction Tuning The process of optimising models to follow specific directions, improving their ability to perform tasks as requested.
Retrieval Infrastructure¶
Embedding Models Specialised neural networks that convert text into numerical vectors that capture semantic meaning. These models are distinct from generative LLMs and are optimised specifically for creating high-quality representations for similarity search. Understanding embedding model selection is crucial for RAG system performance.
Vector Databases Specialised database systems designed to store, index, and efficiently query vector embeddings. Unlike traditional databases optimised for exact matches, vector databases excel at similarity search - finding items that are semantically similar rather than identical. These systems form the foundation of RAG implementations by enabling quick retrieval of relevant documents based on semantic similarity to queries. Leading solutions include Pinecone, Weaviate, Qdrant, Milvus, and vector capabilities in traditional databases like PostgreSQL (with pgvector) and MongoDB Atlas. Key considerations when selecting a vector database include scaling capabilities, filtering options, hosting model, and specialised features like hybrid search.
Distributed RAG Approaches for implementing RAG across multiple servers or regions to improve performance, reliability, and data locality. This includes strategies for sharding document collections, distributing embedding generation, and implementing federated retrieval that respects data sovereignty requirements while maintaining cohesive search capabilities.
Document processing and chunking strategies¶
Markdown Normalisation A document preprocessing technique that converts various document formats (PDFs, HTML, Word documents, etc.) into a standardised markdown representation before chunking and embedding. This approach provides several advantages: it preserves essential structural elements like headings, lists, and tables while stripping away format-specific complexities; it creates a consistent representation across different source formats; and it maintains a human-readable format that's also optimised for NLP processing. Markdown's lightweight syntax preserves document hierarchy and semantic structure while eliminating rendering-specific elements that don't contribute to meaning, resulting in higher-quality chunks that maintain the logical organisation of information.
Token-Based Chunking A document splitting approach that divides text based on token counts rather than character counts, providing more accurate control over chunk sizes for LLM processing. Unlike character-based chunking, this method accounts for how the text will actually be tokenised by the model, preventing unexpected truncation or overflow issues. Token-based chunking ensures that each chunk fits precisely within token limits for embedding generation and context windows, leading to more predictable performance and cost management. This approach is particularly important when working with text containing special characters, code, or non-English languages where character count may correlate poorly with token count.
Recursive Character Text Splitter An advanced chunking technique that recursively splits documents using a hierarchy of delimiters (such as paragraph breaks, sentence boundaries, and word boundaries). This approach attempts to maintain semantic coherence by first trying to split on paragraph boundaries, then falling back to sentence boundaries if chunks are still too large, and finally to word boundaries as a last resort. By respecting the natural structure of documents, recursive splitting creates more meaningful chunks that preserve context and reduce the fragmentation of related information, significantly improving retrieval quality compared to naive chunking methods.
Context-aware Chunking An advanced document splitting approach that preserves semantic meaning rather than breaking text at arbitrary character limits. Unlike simple chunking methods that divide documents by fixed character counts, context-aware chunking analyzes document structure and content to create logical divisions that maintain coherence. This technique preserves the integrity of paragraphs, sections, or semantic units, significantly improving retrieval quality by ensuring that related information stays together and contextual relationships are maintained.
Development Frameworks & Tools¶
LangChain A popular open-source framework for developing applications powered by language models. LangChain provides standardised interfaces and components for working with LLMs, including prompt management, memory systems, document loaders, and output parsers. The framework simplifies common workflows like RAG implementation, chain-of-thought reasoning, and tool integration, allowing developers to focus on application logic rather than infrastructure. Its modular architecture enables flexible composition of LLM capabilities into complex applications while providing abstractions that work across different model providers.
LlamaIndex An open-source framework designed specifically for building RAG applications and connecting LLMs with external data sources. LlamaIndex provides data connectors for diverse sources (PDFs, APIs, databases, etc.), document processing tools, advanced indexing structures, and query interfaces optimised for retrieval-based applications. Unlike more general LLM frameworks, LlamaIndex focuses on solving the specific challenges of data ingestion, chunking, indexing, and structured retrieval, with built-in support for complex query engines, multi-step reasoning over documents, and evaluation metrics for retrieval quality. The framework offers high-level abstractions for common RAG patterns while providing flexibility to customise each component of the retrieval pipeline.
Semantic Kernel Microsoft's open-source framework for integrating AI large language models with conventional programming languages. Unlike frameworks that focus primarily on chaining LLM operations, Semantic Kernel emphasises the seamless integration of AI capabilities into existing software architectures and development workflows. The framework provides a connector-based architecture that supports multiple LLM providers, memory management for conversations, planning capabilities for complex tasks, and structured programming patterns for combining AI with traditional code. Semantic Kernel is particularly valuable for enterprise developers looking to incorporate LLMs into existing .NET, Java, or Python applications while maintaining familiar software engineering practices.
RAG and Related Terminology¶
Naive RAG The simplest implementation of Retrieval-Augmented Generation, often serving as a baseline approach before more sophisticated techniques are applied. Naive RAG follows a straightforward process: convert a query to an embedding, perform a basic similarity search against a document collection, retrieve the top-k most similar chunks based on vector similarity alone, and pass these chunks directly to the LLM along with the query.
While functional, this approach has several limitations: it doesn't account for the relevance of retrieved documents beyond vector similarity, lacks mechanisms to handle queries requiring information from multiple documents, and doesn't optimise the context window usage when sending retrieved content to the LLM. Understanding these limitations helps practitioners recognise when more advanced RAG techniques become necessary for their specific use cases.
Query Transformation The process of reformulating a user's original query to improve retrieval results. This might involve expanding the query with related terms, breaking complex questions into simpler ones, or extracting key entities to focus the search.
Query Expansion A technique that broadens the original query by generating multiple related queries to improve retrieval coverage. Unlike simple query transformation that modifies the original query, query expansion creates several distinct queries that approach the information need from different angles. For example, a question about "solar panel efficiency" might be expanded to include separate queries about "photovoltaic performance," "solar energy conversion rates," and "factors affecting solar panel output." These expanded queries run in parallel, retrieving a more diverse set of relevant documents than a single query could capture, particularly for complex or multifaceted questions.
Semantic Drift Detection A quality control technique that measures how far a transformed query has deviated from the original query's meaning. By calculating the semantic distance (typically using cosine similarity between embeddings) between the original and transformed queries, the system can detect when a transformation has drifted too far from the intended meaning. If the semantic distance exceeds a predetermined threshold, the system can reject the transformation, try alternative transformations, or fall back to the original query. This safeguard prevents query transformation from inadvertently changing the user's intent, ensuring that retrieval remains aligned with the original information need even after query optimisation. Can be known as Query Transformation Validation.
Retrieval Quality A measure of how effectively a RAG system finds relevant information. This encompasses both recall (finding all relevant documents) and precision (avoiding irrelevant results).
Dense Retrieval A retrieval approach using neural networks to create dense vector representations of both queries and documents, enabling semantic matching beyond simple keyword overlap.
Sparse Retrieval Methods like BM25 or TF-IDF that rely on keyword matching and statistical analysis rather than deep semantic understanding. Often faster but less nuanced than dense retrieval.
Hybrid Retrieval Combining both dense and sparse retrieval methods to leverage their complementary strengths, often achieving better overall performance.
BM25 (Best Matching 25) A ranking function used in traditional information retrieval that scores documents based on term frequency and document length. Unlike simple keyword matching, BM25 accounts for how common terms are in the corpus and penalises excessively long documents, making it effective for finding relevant text passages without requiring vector embeddings.
TF-IDF (Term Frequency-Inverse Document Frequency) A statistical measure that evaluates how important a word is to a document within a collection. It weighs terms based on how frequently they appear in a document (TF) but penalises terms that are common across many documents (IDF). This classic information retrieval technique remains valuable in hybrid RAG systems, particularly for exact matching of specific terms.
Reranking A second-pass evaluation of retrieved documents that reorders them based on their relevance to the query. While initial retrieval often uses faster but less precise methods, reranking applies more sophisticated algorithms to ensure the most relevant information appears first.
RRF Algorithm (Reciprocal Rank Fusion) A method for combining results from multiple search approaches by weighting them based on their reciprocal ranks. RRF provides a mathematically sound way to merge results from different retrieval systems without requiring score normalisation, effectively leveraging the strengths of diverse search methodologies while mitigating their individual weaknesses.
Cross-Encoder Reranking A sophisticated technique that performs deep analysis on potential search matches, dramatically improving retrieval quality. Unlike bi-encoders that encode queries and documents separately, cross-encoders evaluate query-document pairs together, enabling more nuanced relevance assessment at the cost of higher computational requirements. This approach significantly improves precision by capturing complex relevance signals that simpler retrieval methods miss.
Retrieval Depth vs. Breadth The trade-off between retrieving more detailed information from fewer sources versus broader information from more sources, which affects response comprehensiveness.
Embedding Management Strategies for effectively handling text embeddings in production systems. Best practices include implementing embedding caching to avoid redundant processing, maintaining version control for embeddings to track changes over time, selecting appropriate embedding models for specific use cases, considering dimensionality trade-offs between precision and efficiency, and applying batch processing for improved throughput when generating embeddings. Effective embedding management is crucial for retrieval system performance and cost efficiency.
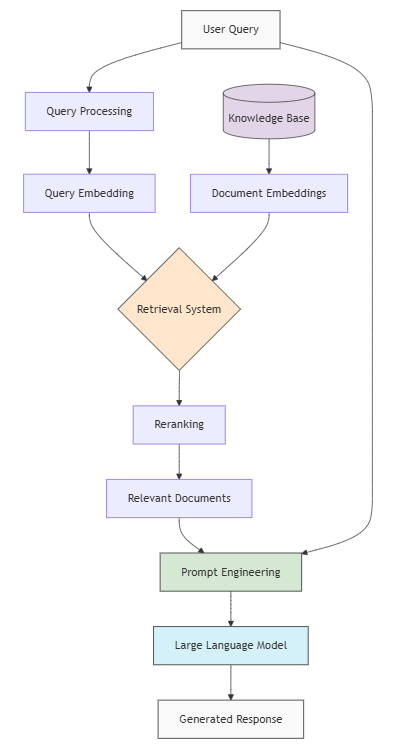
How these techniques are combined together into a Retrieval-Augmented Generation (RAG) process:
Temperature Settings for RAG¶
RAG systems typically work best with lower temperature settings since they focus on factual information retrieval and accuracy. The appropriate setting depends on your specific use case:
Very Factual Q&A (0-0.1) For purely factual responses where creativity is unnecessary and consistency is critical. Ideal for retrieving specific information like product specifications, policies, or technical details.
Informational Content with Synthesis (0.1-0.3) When the system needs to integrate multiple pieces of retrieved information coherently. This range balances factual accuracy with enough flexibility to connect concepts from different sources.
Conversational or Explanatory RAG (0.3-0.5) When you want the model to explain concepts in more accessible ways or provide slightly more diverse responses while maintaining factual accuracy. Useful for customer-facing applications that need to sound natural while remaining grounded in retrieved information.
Higher temperature settings (above 0.5) are generally not recommended for RAG systems as they increase the risk of hallucination and reduce the influence of the retrieved content.
Continue with advanced terminology¶
Pushing the Boundaries: Advanced Techniques for Production LLM & RAG Systems
Chris Thomas is an AI consultant helping organisations validate and implement practical AI solutions.